Indice del volumen Volume index
Comité Editorial Editorial Board
Comité Científico Scientific Committee
- Es el único método para establecer directamente la incidencia.
- La exposición puede determinarse sin el sesgo que se produciría si ya se conociera el resultado; es decir, existe una clara secuencia temporal de exposición y enfermedad.
- Brinda la oportunidad para estudiar exposiciones poco frecuentes.
- Permite evaluar resultados múltiples (riesgos y beneficios) que podrían estar relacionados con una exposición.
- La incidencia de la enfermedad puede determinarse para los grupos de expuestos y no expuestos.
- No es necesario dejar de tratar a un grupo, como sucede con el ensayo clínico aleatorizado.
- Pueden ser muy costosos y requerir mucho tiempo, particularmente cuando se realizan de manera prospectiva.
- El seguimiento puede ser difícil y las pérdidas durante ese periodo pueden influir sobre los resultados del estudio.
- Los cambios de la exposición en el tiempo y los criterios de diagnóstico pueden afectar a la clasificación de los individuos.
- Las pérdidas en el seguimiento pueden introducir sesgos de selección.
- Se puede introducir sesgos de información, si la identificación de la enfermedad puede estar influenciada por el conocimiento del estado de exposición del sujeto.
- No son útiles para enfermedades poco frecuentes porque se necesitaría un gran número de sujetos.
- Durante mucho tiempo no se dispone de resultados.
- Evalúan la relación entre evento del estudio y la exposición a sólo un número relativamente pequeńo de factores cuantificados al inicio del estudio.
ESTUDIOS DE COHORTE: SUS TIPOS Y USOS
Ángela María Benjumea Salgado. MD.
Universidad de Caldas. Manizales. Colombia.
Email: ambsco4 @ gmail.com
Rev Electron Biomed / Electron J Biomed 2020;1:27-43.
Comentario del revisor Dr. Sergio Terrasa. Departamento de Investigación. Hospital Italiano de Buenos Aires, Argentina.
Comentario del revisor Raúl Martin Chaparro, MD. MSc. Especialista en Epidemiologia. Cátedra de Salud Pública. Universidad de Buenos Aires. Argentina.
RESUMEN
Los estudios de cohorte son estudios de carácter longitudinal, observacional y analíticos; es un diseńo de investigación clínica primaria, excepcionalmente útil porque estudia causalidad y los efectos de las exposiciones. Se toma a un grupo de sujetos expuestos a un potencial factor causal y a otro grupo no expuesto, y se busca en el tiempo, quienes desarrollan el desenlace, esto es, la incidencia del evento. Si al finalizar el período de observación la incidencia de la enfermedad es mayor en el grupo de expuestos, se puede concluir que existe una asociación estadística entre la exposición a la variable y la incidencia de la enfermedad.
Existen diferentes tipos de estudios de cohorte dependiendo de la relación temporal entre el inicio del estudio y la ocurrencia del evento; los estudios de cohorte se han clasificado como: prospectivos o concurrentes, retrospectivos (o históricos) y ambiespectivos, cada uno con sus características, beneficios y limitaciones propias. El diseńo de estudios de cohorte incluye una selección cuidadosa de la población de estudio expuesta y no expuesta, un seguimiento detallado y un método de análisis acorde al evento de interés estudiado; permite estimar, riesgos de aparición de eventos, tiempos de supervivencia, tasas de incidencias. A la fecha se reportan herramientas de evaluación crítica de estudios observacionales como la guía STROBE y MOOSE.
La finalidad de esta revisión y recopilación de la literatura es dar pautas claras y precisas para todos los niveles de enseńanza y aprendizaje en el tema de interés.
PALABRAS CLAVE: Cohorte. Estudios de cohorte. Diseńo de investigación clínica. Análisis del diseńo.
ABSTRACT:
Cohort studies are longitudinal, observational, and analytical studies; is a primary clinical research design, exceptionally useful because it studies causality and the effects of exposures. A group of subjects exposed to a potential causal factor and another unexposed group, and it is sought in time, who they develop the outcome, that is, the incidence of the event. If at the end of the period observation the incidence of the disease is higher in the group of exposed, it can be conclude that there is a statistical association between exposure to the variable and the incidence of the disease.
There are different types of cohort studies depending of the temporal relationship between the start of the study and the occurrence of the event; the studies of cohort have been classified as: prospective or concurrent, retrospective (or historical) and ambitious, each with its own characteristics, benefits and limitations own. Cohort study design includes careful selection of the population exposed and unexposed study method, detailed monitoring and method of analysis according to the event of interest studied; allows to estimate, risks of occurrence of events, survival times, incidence rates. To date tools are reported critical evaluation of observational studies such as the STROBE and MOOSE guide.
The purpose of this review and compilation of the literature is to give clear and precise guidelines for all levels of teaching and learning in the subject of interest.
KEY WORDS: Cohort. Cohort studies. Clinical research design. Design analysis.
INTRODUCCIÓN
Los diseńos de investigación se clasifican en dos grandes grupos de acuerdo al grado de control que tendrá el investigador sobre las variables y factores, tanto internos como externos a estudiar, así, un diseńo puramente experimental es aquel en el que el investigador tiene control total sobre todas las variables y factores en estudio; y cuando esto no es posible, entonces se debe emplear un diseńo observacional.
Otra forma de clasificarlos se relaciona con el momento en que se llevará a cabo la obtención y el análisis de la información, cuando la información es captada en el pasado y analizada en el presente, se dice que el estudio es retrospectivo, pero si las variables se miden en el desarrollo de la investigación y se analizan al concluirlo, entonces el diseńo es prospectivo.
El número de veces que se miden las variables en un estudio es otra forma de clasificar el diseńo de investigación, cuando solamente se hace una medición de las variables el diseńo es transversal y es longitudinal cuando el investigador lleva a cabo un seguimiento de una cohorte de individuos en los que realiza mediciones a intervalos de tiempo definidos. Finalmente, cuando el estudio de investigación tiene por objetivo documentar las condiciones, actitudes o características de la población o poblaciones en estudio, el diseńo de investigación es descriptivo.
Por otro lado, un diseńo analítico busca explicar la relación, generalmente causal, entre los factores en estudio, son aquellos en los que el investigador permanece a la expectativa, ya sea de los efectos de la exposición en los sujetos de estudio o de la asociación entre los factores de riesgo y el evento final1 (tabla 1).

La característica que define a los estudios de cohorte es que los sujetos de estudio se eligen de acuerdo con la exposición de interés; en su concepción más simple se selecciona a un grupo expuesto y a un grupo no expuesto y ambos se siguen en el tiempo para comparar la ocurrencia de algún evento de interés2. El objeto de estudio son los individuos, y tratan de explicar o encontrar causalidad; esto es, si se observa una asociación entre una exposición y una enfermedad u otro evento, se quiere averiguar si es verdaderamente causal3.
Los estudios de cohorte son excepcionalmente útiles en investigación clínica por su valor en el estudio de la causalidad y los efectos de exposiciones de interés3. Cohorte, del latín cohorts: séquito, agrupación; término usado entre los romanos para denominar un cuerpo de infantería que comúnmente constaba de 500 hombres, y era la décima parte de una legión. Una cohorte es un grupo de personas que tienen características comunes y que pueden ser observados por un periodo de tiempo para observar un evento de interés; hay tres criterios a tener en cuenta al elegir una cohorte4:
1. El grupo no debe tener la enfermedad en estudio al momento de empezar la investigación.
2. Debe ser observada en el periodo de tiempo suficiente y significativo.
3. Los sujetos del estudio deben mantenerse durante el tiempo de seguimiento.
Una vez mencionado esto, es importante hacer claridad que se puede hacer estudios de investigación con una cohorte sin que sea un diseńo tipo estudio de cohorte. En éste artículo se hará una revisión temática y metodológica del tipo de estudio de cohorte, con sus características, aplicaciones, diseńo y sus pasos, análisis y evaluación.
Aplicaciones y usos
Existen múltiples aplicaciones en las que pueden utilizarse los estudios de cohorte de acuerdo con su dimensión en el tiempo, entre ellos, la edad que es un determinante de incidencia; el tiempo calendario, donde los antecedentes y exposición pueden variar con el tiempo, el factor de riesgo como la asociación de consumo de tabaco con cáncer de pulmón; para estudiar pronóstico, en intervención preventiva e intervención terapéutica4 (Tabla n. 2).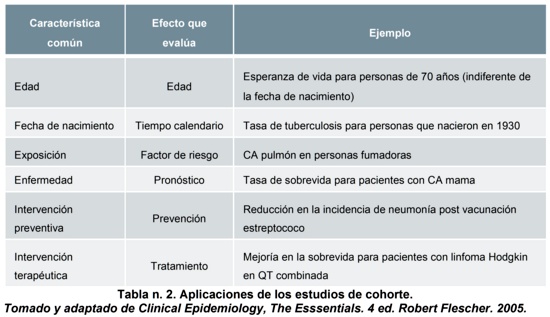
Investigación de brotes epidemiológicos
En estos casos, los estudios de cohorte suelen ser retrospectivos porque tanto el brote como la posible exposición ya ocurrieron. El objetivo es determinar qué exposiciones ocurrieron en las cohortes en el pasado para explicar los casos de enfermedad5.
Estudios de causalidad
En estos casos, los estudios suelen ser prospectivos. Por ejemplo, el estudio de asociación entre psicopatología y migrańa5.Evaluación de intervenciones en educación
Se pueden conducir estudios prospectivos y bidireccionales. Cobran especial interés cuando se desea evaluar el efecto de intervenciones educativas5.Otras aplicaciones
Es interesante mencionar el uso de bases de datos a gran escala, también denominadas "Big-Data", que permite realizar investigación biomédica y de gestión en salud, con un alto volumen de datos respecto de diversidad biológica, clínica, ambiental y de estilos de vida de grandes grupos de sujetos, en uno o diversos puntos temporales. Estos datos provienen de diversas fuentes, como registros electrónicos de salud, registros de pacientes y bases de datos de mediciones, estudios clínicos publicados, indicadores socioeconómicos, información ocupacional, aplicaciones móviles o monitoreo ambiental5.
Ventajas de los estudios de cohorte2
Desventajas de los estudios de cohorte 2
Tipos de estudio
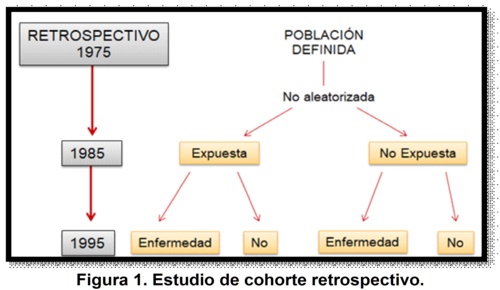
Dependiendo de la relación temporal entre el inicio del estudio y la ocurrencia del evento, los estudios de cohorte se han clasificado como: prospectivos o concurrentes, retrospectivos (o históricos), y ambiespectivos3. Los estudios de cohorte histórica reconstruyen la experiencia de la cohorte en el tiempo, por esta razón dependen de la disponibilidad de registros para establecer exposición y resultado.
La validez del estudio dependerá en gran medida de la calidad de los registros utilizados3 (gráfica n. 1); las diferencias principales con los estudios prospectivos o concurrentes, son que la identificación de la cohorte, las mediciones basales, el seguimiento y los desenlaces ya se han producido cuando se inicia el estudio5.
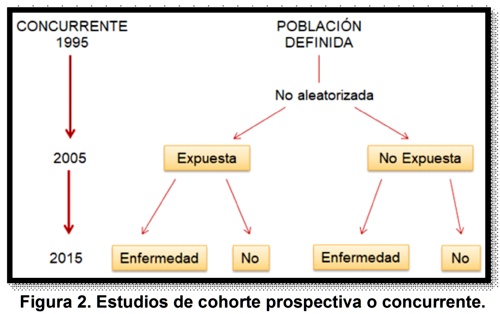
En contraste, en las cohortes prospectivas es el investigador quien documenta la ocurrencia del evento en tiempo venidero en la población en estudio, por lo que la exposición y el resultado se valoran de manera concurrente, y la calidad de las mediciones puede ser controlada por los investigadores3 (gráfica n. 2); en ellos se puede obtener información detallada, precisa y objetiva de la exposición, lo que permite estudiar el efecto en un subgrupo de sujetos sometidos a un determinado grado de exposición, incluso clasificar la exposición en diferentes grados para evaluar una posible relación causa-efecto5; el seguimiento de este subtipo de estudio es el mayor desafío debido a que se emplea a un número importante de sujetos y durante períodos habitualmente prolongados de tiempo en ambas cohortes involucradas, es por esto, que se considera que los estudios de cohorte prospectivas son poco eficientes para el estudio de exposición o eventos de interés que tienen períodos de latencia prolongados, pues requieren de seguimientos muy largos lo cual incrementa de forma notable los costos y el riesgo de pérdida tanto del sujeto como del investigador5.
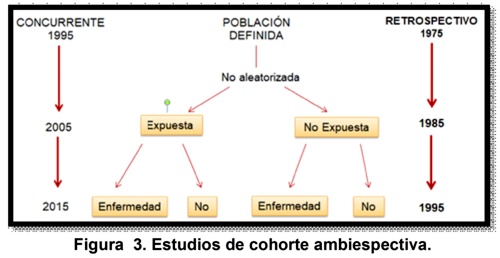
En el tipo de estudio ambiespectivo, la exposición se toma de datos ocurridos en el pasado (estudio de cohorte retrospectivo) y el seguimiento y la medición del resultado se mira hacia el futuro 6(gráfica n. 3). En el estudio anidado de casos y controles, es necesario tener disponible la información pertinente de exposición y enfermedades presentes en el momento de inicio del estudio y tener en cuenta que la Información secundaria no prediseńada es una fuente de sesgos, por ello, la disponibilidad y la calidad de esta información es de relevancia para la selección del tipo de estudio; por ejemplo: existe una base de datos disponible de un grupo de pacientes ingresados a UCI con diagnóstico de infarto agudo de miocardio y cuyos datos de ingreso, tratamiento, pronostico y desenlaces fueron cuidadosamente registrados. żEl uso de estreptoquinasa se asoció con mayor mortalidad?, se parte la base de datos en expuestos y no expuestos y se compara la frecuencia de aparición del desenlace muerte3,6.
Con relación al tipo de población, las cohortes construidas pueden ser fijas, también llamadas cerradas, y dinámicas. Cerradas o fijas son las cohortes que por diseńo de estudio no consideran la inclusión de población en estudio más allá del periodo de reclutamiento fijado por los investigadores, y dinámicas son aquellas cohortes que consideran la entrada y salida de nuevos sujetos de estudio durante la fase de seguimiento, por lo que el número de miembros puede variar a través del tiempo. Los participantes entran o salen de la cohorte cuando cumplen criterios de elegibilidad, incorporando la aportación ańos-persona desde el momento de inclusión en el estudio2.
Diseńo de un estudio de cohorte
De una población general con características similares se selecciona un grupo de personas, las cuales conocen desde el inicio la información acerca del factor de exposición o de estudio. Este grupo cohorte se divide no aleatoriamente entre expuestos y no expuestos y partir de este momento se hace un seguimiento por un tiempo determinado, para definir al final quienes de esos grupos si desarrollaron enfermedad o evento de interés y quiénes no4 (figura 4).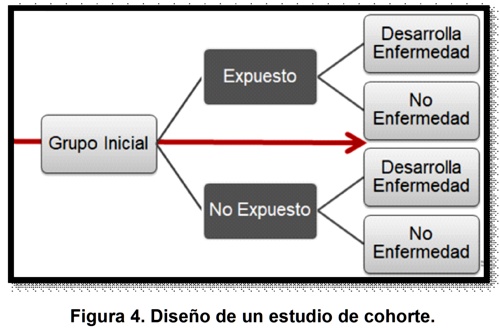
Pasos y estructura
1. La selección
Un grupo de cohorte debe tener características similares entre sí, que no tenga la enfermedad o condición de interés y que esté expuesto de manera estable al factor que se desea investigar. Con respecto a las fuentes de datos potenciales debe tenerse en cuenta el grado de exposición, la disponibilidad de la información acerca de la exposición, el grado de representatividad de la población de interés y la posibilidad de detectar el evento de interés. Debe además tenerse en cuenta que sea una cohorte susceptible de seguirse y con posibilidad de ampliar información si se requiere y debe poderse detectar el inicio de la exposición y sus cambios. Para asegurar una buena elección del grupo los criterios de inclusión y exclusión deben ser definidos con precisión6.El muestreo consiste en incluir a todos los miembros o una fracción de los sujetos integrantes de la población fuente, si la fracción de muestreo es de 1 (100% población fuente) tanto la precisión (error aleatorio o precisión de muestreo) como la validez (ausencia de sesgo) serán perfectas y cuando la fracción de muestreo es < 1 indica que no es factible o que es ineficiente incluir toda la población fuente; la cantidad de sujetos incluidos y la forma de muestreo influyen en la precisión de sus estimadores y en su validez, para asegurar que los sujetos sean una representación estadística no sesgada de la distribución de los atributos y características se debe hacer un proceso de muestreo aleatorio, y en otros casos, solo se requiere una muestra de sujetos que incluya el rango de características de interés para lo cual se hace una un muestreo no probabilístico por conveniencia 7.
2. Selección del grupo control o no expuesto
Debe tener características muy similares entre si y también en relación con la primera cohorte seleccionada; se debe asegurar que este grupo no tenga la enfermedad o condición de interés y que no esté expuesto al factor en estudio, ni se prevea razonablemente que lo vaya a estar. Debe existir un formato especial diseńado para llevar a cabo el estudio y las fuentes de información pueden ser tomadas de historias clínicas o médicas, certificados de defunción, registros nacionales, cuestionarios locales, seguros médicos, documentos de empleo6. Esta cohorte no expuesta puede dividirse para el análisis según los grados de exposición al factor de estudio, en éste caso se configuran varias cohortes definidas por diferentes grados de exposición y que permitan evaluar las relaciones entre dosis de exposición y respuesta (riesgo del evento)7.3. Medición de evento resultado.
Los eventos de estudio pueden ser:a) evento simple (fijo en el tiempo) o evento raro (muerte o incidencia de enfermedad). En ambos casos, al observar el evento en cada unidad de análisis el seguimiento termina;
b) eventos múltiples o raros (enfermedades recurrentes, sintomatología o eventos fisiológicos). Al presentar el evento el individuo deja de estar en riesgo por lo que ya no cumple con el criterio de permanencia en la cohorte. Se puede reiniciar el seguimiento cuando se restablece el riesgo, es decir, cuando hay curación y el individuo vuelve a estar en riesgo de presentar el evento;
c) modificación de medida eje (por ejemplo la función broncopulmonar en el tiempo, modificación de la función pulmonar hacia un aumento o disminución), que son evaluados mediante tasa de cambio, y
d) marcadores intermedios del evento (cuenta de apolipoproteínas A y B como marcadores de predisposición a enfermedad cardiovascular)2.
El seguimiento de los grupos se hace por el tiempo que sea razonable, esto depende de la fisiopatología de la enfermedad, tiempos de latencia y preclínicos, y métodos empleados para la detección6. El periodo de seguimiento puede abarcar ańos, meses, semanas o días, dependiendo de la frecuencia del evento estudiado, en ocasiones los sujetos entran a la cohorte en diferentes fechas y la cohorte se considera ensamblada no en una fecha determinada, sino en un momento defino del curso clínico del evento de interés, por ejemplo un investigador está interesado en evaluar si la edad al momento de hacerse el diagnostico de leucemia linfoide aguda en nińos menores de 15 ańos es un factor que afecta el curso clínico de la enfermedad, en este caso el punto de partida ocurre cuando, después de confirmado el diagnostico, cada paciente inicia el tratamiento7.
Dos momentos definen el periodo de seguimiento: el examen inicial (medición basal) y el final del seguimiento, el tiempo transcurrido entre el inicio o momento del ensamble y la ocurrencia del evento de interés se denomina tiempo de incidencia y si el evento es la muerte el tiempo de incidencia corresponde a la duración del tiempo de supervivencia y si el evento es una recaída o una complicación, el tiempo de incidencia recibe el nombre de tiempo libre de recaída7.
El inicio del seguimiento depende del tipo de cohorte: si es cerrada o dinámica, ya que en el caso de esta última, el inicio del seguimiento se define para cada participante a través de un largo periodo de tiempo2. El seguimiento, dependiendo del evento de interés, puede ser activo o pasivo. Activo es aquel en el que se utilizan contactos repetidos por diversos medios; nueva entrevista y obtención de muestras, como cuestionarios auto aplicables o llamadas telefónicas. El seguimiento pasivo es el que se realiza mediante búsqueda sistemática en sistemas de información de registros preestablecidos (registros de cáncer, hospitalarios, registro civil, entre otros) 2.
4. Análisis.
Una de las fortalezas de los estudios de cohorte es la posibilidad de calcular medidas de asociación; son indicadores epidemiológicos que evalúan la fuerza con la que una determinada enfermedad o evento de interés se asocia con un determinado factor de exposición, que se presume como su causa, también se pueden considerar como comparaciones de incidencias: incidencia del evento de interés (EI) en expuestos al factor en estudio vs incidencia del EI en sujetos no expuestos al factor en estudio5.Las medidas de asociación e impacto cuantifican la relación entre variables de exposición o factores de riesgo y la enfermedad o EI; es decir, la magnitud de la diferencia observada. Las medidas de asociación más sólidas se calculan utilizando la incidencia, ya que ésta, permite establecer que el efecto del EI es posterior a la exposición. Para ello, se ha de construir una tabla de contingencia o tetracórica, en la que se detallen los datos del desarrollo o manifestación del EI en las cohortes de expuestos y no expuestos5 (figura 5).
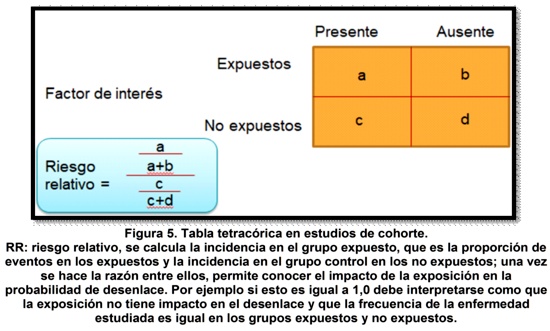
De este modo, existen medidas de efecto y medidas de impacto. Ambas, permiten conocer la magnitud cuantitativa de la fuerza de asociación entre dos variables. Se entiende como medidas de efecto, como aquellos que se basan en el cálculo de un cociente; por lo que permiten cuantificar discrepancias en la ocurrencia de un EI en grupos que difieren en la existencia de cierta variable. Estas son: la razón de tasas de incidencia o riesgo absoluto (RA) y el riesgo relativo (RR)5 (tabla 3).
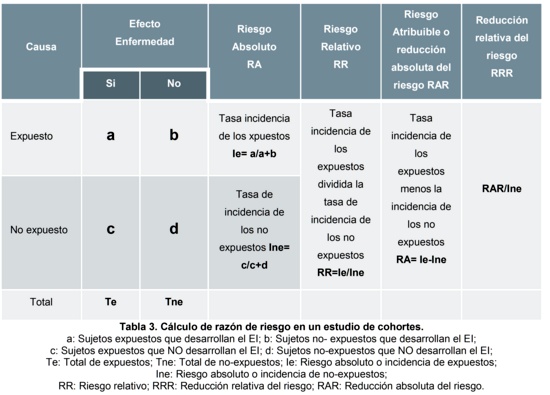
Se entiende como medidas de impacto, a aquellas que se basan en las diferencias. En general, indican la contribución de un determinado factor en la producción del EI entre los que están expuestos a él. Por este motivo, se dice que las medidas de impacto indican el riesgo de enfermar que podría evitarse si se eliminara la exposición, y están representadas por: la reducción absoluta de riesgo (RAR), la reducción relativa de riesgo (RRR), el número necesario a tratar (NNT) o a dańar (NND)5 (tabla 3).
Riesgo relativo (RR). Representa la fuerza de la asociación entre exposición y EI. Revela la probabilidad que se desarrolle el EI en los expuestos a un factor de riesgo (FR) respecto de los no expuestos. Si la razón RR es mayor de 1,0 debe interpretarse como que la exposición aumenta el riesgo de desenlace, un RR de 4,0 significa que el desenlace es cuatro veces más frecuente en aquellos expuestos cuando se los compara con los no expuestos. El RR puede ser menor de 1,0, lo que ocurre cuando la exposición tiene un efecto protector. Siempre es recomendable presentar un RR con su respectivo intervalo de confianza del 95%, ya que esto permite conocer el intervalo en que se encuentra la verdadera magnitud del efecto estudiada y medida en el 95% los casos (determina el nivel de precisión)6.
Reducción absoluta de riego (RAR). O Reducción Atribuible del Riesgo, o Riesgo Atribuible. Corresponde a la diferencia entre el riesgo en el grupo sin FR en estudio y el riesgo en el grupo con FR en estudio. Es decir, expresa la reducción del riesgo de aparición del EI en el grupo de sujetos con la intervención en estudio respecto de los sujetos que no reciben esta intervención, que reciben un placebo o una intervención diferente. Un RAR = 0, significa que no hay asociación entre el FR y el EI, un RAR < 0, significa asociación, es decir que el FR se asocia a mayor ocurrencia del EI. Por último, un RAR > 0, significa asociación negativa, es decir que el FR se asocia a menor ocurrencia del EI8.
Reducción relativa de riego (RRR). O fracción atribuible o diferencia relativa de riesgo. Útil para expresar la efectividad de una intervención. Corresponde al cociente entre la RAR y el riesgo del grupo no expuesto. Indica así que el riesgo del grupo tratado se reduce en un porcentaje del riesgo del grupo no expuesto8.
Proporción de incidencia y tasa de incidencia
Cuando el tiempo incidente hasta un evento no puede ser determinado en todos los sujetos del estudio (pérdida, muerte por otra causa, terminación del tiempo de seguimiento), se debe analizar la información de una manera diferente.
Una forma consiste en calcular la proporción de sujetos en riesgo que presentaron el desenlace en algún momento del intervalo observado, en el numerador se cuentan los sujetos con el desenlace y en el denominador, todos los sujetos en riesgo al comienzo del período y cuyo destino se conoce al final del intervalo observado, esta medida es la proporción de incidencia o incidencia acumulada, solo se puede calcular en los sujetos de quienes se conoce cómo están al final del período de observación7.
Si el destino de algunos de los miembros de la cohorte no es conocido al final del intervalo de observación, en vez de excluir a quienes tienen seguimiento inferior al periodo estipulado se puede calcular la tasa de incidencia la cual es el cociente o la razón entre el número de eventos de interés y la cantidad de tiempo-persona en riesgo acumulada durante el intervalo observado
Por ejemplo, un total de 24 nińos con diagnóstico de leucemia linfoide aguda se les hace seguimiento hasta por 5 ańos (60 meses), 19 de ellos no fallecen a lo largo de los primeros 6 meses y entran en remisión, 2 (uno a los 24 meses que fallece y otro a los 37 meses recae) presentan recaída durante el tiempo de seguimiento y 17 completan seguimiento sin evidencia de actividad de la enfermedad; entonces, cada uno de los 17 sujetos sin evidencia de actividad de la enfermedad contribuye con 60 meses en riesgo y la sumatoria de todos los tiempos en riesgo aportados por la cohorte es: 16 meses (de los 5 nińos fallecidos antes de 6 meses) + 24 meses (1 fallecido) + 37 meses (recae) + 1020 (17 sin recaída x 60 meses de seguimiento)= 1097 meses/persona.
La tasa de incidencia de muerte o de mortalidad durante los primeros 5 ańos después del diagnóstico es: 6 fallecimientos/ 1097 meses-persona= 5,47 muertes por 1000 persona/ mes7.
Fuentes de error sistemático en el ensamblaje de la cohorte
Los estudios que afecten el ensamblaje de una cohorte pueden afectar la validez interna del estudio o comprometer solo la validez externa de los resultados7.Sesgo de selección
Cuando se define la población fuente, las distribuciones de las características de este subconjunto pueden diferir sistemáticamente de las distribuciones en la población en la que se quiere estudiar; esto ocurre cuando la población accesible es solo un subconjunto específico de la población elegible. Ejemplo: se quiere estudiar el riesgo de enfermedad de transmisión sexual (ETS), la fuente de participantes es la consulta de vida sexual activa y segura de una empresa promotora de salud (EPS) particular de una zona o localidad específica, caracterizada por alta prevalencia de ETS genital anal. No todas las personas de esa EPS que tienen vida sexual activa acuden a la consulta, quienes asisten a esta consulta son más cuidadosos con las prácticas sexuales y su riesgo de presentar ETS es menor.Este sesgo de selección causa dos efectos: a) la población fuente es una subrepresentación sistemática del riesgo de enfermedad de transmisión sexual en la población real de interés, lo cual hace que la extrapolación de los hallazgos a esa población de la consulta especial de la EPS sea apropiada solo para el subconjunto de los que asisten a una consulta o programa y b) debido a que el factor de riesgo más importante para enfermedad de transmisión sexual genital anal es el uso o no de preservativo, al hacer que todos usen preservativo independientemente del lugar de procedencia, atenúa o elimina la asociación entre procedencia y riesgo de ETS.
Esto ocurre porque el factor de riesgo de interés (procedencia) tiene una asociación causal al desenlace, que no es directa sino mediada, por el patrón de uso de preservativo (se espera que esta conducta sea diferente de acuerdo al lugar de procedencia). Al seleccionar como población fuente a los pacientes de esta consulta específica, se elimina el uso diferencial de preservativo según su zona de procedencia, esto produce un tipo especial de sesgo, llamado sesgo de sobreapareamiento y su efecto es desviar sistemáticamente los estimativos de asociación hacia la no diferencia entre los diferentes niveles de exposición7.
Sesgos en el muestreo
El investigador a través del muestreo y aplicación de criterios de inclusión y exclusión, invita a los sujetos a participar, los sujetos son libres de aceptar o no. Existe evidencia empírica de que los sujetos que aceptan participar pertenecen a subpoblaciones sistemáticas diferentes de las poblaciones que no aceptan, relacionado con hábitos de vida saludables, patrones de uso de servicios de salud y cumplimiento de recomendaciones médicas.La aceptación diferencial (autoaceptación) puede comprometer la validez externa y en ocasiones la validez interna. Por esto es aconsejable medir y comparar las características generales de quienes sí y no aceptan7.
Sesgos en la asignación
Los sesgos que ocurren en la asignación pueden afectar de forma significativa la estimación de las asociaciones estudiadas. Clasificar correctamente la exposición es uno de los pasos críticos y vulnerables en la planeación y conducción de los estudios de cohorte. Hay dos tipos de error sistemático que afectan la asignación:a) mala clasificación. La mala clasificación diferencial consiste en clasificar como pacientes expuestos a un subgrupo de personas no expuestas, o viceversa. Esto es, el uso de criterios diferentes para definir la exposición produce una mala clasificación, por ejemplo al definir una exposición a tabaco, en la categoría de fumador, la cual resulta ser muy sensible porque no se escapa ningún verdadero fumador pero es muy poco especifica porque tiene falsos positivos; por el contrario la definición de no fumador es muy específica pero poco sensible, muchas personas que en realidad solo han tenido una exposición mínima y no significativa al consumo de cigarrillo son clasificadas como fumadoras y agrupadas junto con verdaderos fumadores de exposición significativa. Esto diluye el efecto del cigarrillo en el riesgo de aparición del cáncer de vejiga y lleva a subestimar la verdadera magnitud de la asociación7.
La mala clasificación no diferencial es ineludible debido a que ningún sistema de medición está exento de error de clasificación, el investigador debe escoger una prueba con la mejor capacidad discriminativa posible, pero siempre en todos las casos anticipar que éste tipo de mala clasificación sesga los resultados hacia la atenuación o la desaparición de la asociación.
Un ejemplo claro que aparece en la literatura de referencia es clasificar una cohorte de fumadores y no fumadores a través de pregunta con habilidad discriminativa: żconsidera usted que ha sido fumador alguna vez en su vida?, revisión de la historia clínica y pregunta a un amigo, se clasificaron 2000 sujetos en total, 1500 como fumador y 500 como no fumador; al hacer una validación de la exposición por medio de entrevista estructurada, se halló, que en realidad, había 500 no fumadores que habían sido erróneamente clasificados como fumadores7.
Cuando el estudio encuentra una diferencia entre las incidencias del desenlace entre grupo expuesto y no expuesto, se puede afirmar que la diferencia si existe, pero que la magnitud podría ser mayor que la hallada en el estudio, por el sesgo (pese a tener un sesgo en su contra); la mayor dificultad aparece cuando el estudio no encuentra diferencias, porque podría ser que en verdad no las hay, o que si las hay no pueden ser evidenciadas debido al sesgo hacia la no diferencia producido por la mala clasificación no diferencial;
b) desbalance de la distribución de potenciales factores de confusión. En los estudios de cohorte el investigador debe anticipar la probabilidad de confusión y controlar sus efectos en el diseńo, por lo tanto el factor de confusión debe ser identificado desde el diseńo del estudio y medirlo en los sujetos del estudio ya sea para excluir o controlar. Otro ejemplo tomado y adaptado de la literatura de referencia para dar mayor claridad a este sesgo es estudiar de la consulta de pacientes crónicos de una EPS la asociación proporcional entre diagnóstico de bronquitis crónica y consumo de café, al ensamblar la cohorte se encuentra que los sujetos clasificados como tomadores de café reportan que fuman mucho más que lo que reportan los no consumidores de café; por lo tanto la conclusión es que la observación de bronquitis entre consumidores de café es producto de la confusión con el tabaquismo, donde los tomadores de café fuman mucho más7.
Instrumentos para reportar resultados y evaluar los Estudios de Cohorte
Iniciativa STROBE (Strengthening the Reporting of Observational Studies in Epidemiology). Es una guía que fue creada con el objetivo de ser una ayuda de utilidad en la conducción de estudios observacionales y en la presentación de los reportes (cómo fue planeado, diseńo, resultados, conclusiones), así como debilidades y fortalezas; estas guías le permiten a editores de revistas, revisores, pares académicos, lectores hacer una evaluación crítica de la literatura, es además de vital importancia esta guía de evaluación, pues al cumplir a cabalidad con la lista de chequeo, un artículo que puede ser incluido en revisiones sistemáticas a futuro9.
Se publicó en 2007 y fue actualizado en 2008. Es una lista de chequeo compuesta por 22 ítems distribuidos en 6 dimensiones (título, resumen, introducción, metodología, resultados y discusión), que deben ser consideradas en la comunicación de resultados de diseńos observacionales (estudios transversales, estudios de casos y controles y estudios de cohorte)10.
Propuesta MOOSE (Meta-analysis of observational studies in epidemiology). Se publicó en 2000. Es una propuesta de la asociación médica americana para el reporte de meta-análisis de estudios observacionales, que consiste en una lista de comprobación de datos específicos que incluyen estrategia de búsqueda, métodos, resultados, discusión y conclusión y que puede ser usada por editores, revisores y lectores11.
Escala MInCir-terapia (Metodología de Investigación en Cirugía). El grupo MInCir, publicó en 2009, una propuesta válida y confiable, para la realización de revisiones sistemáticas y meta-análisis en escenarios de terapia, prevención, etiología y dańo; con diferentes tipos de diseńos (incluidos los Estudios de Cohorte). Permite evaluar calidad metodológica. Está compuesta por 3 dominios (diseńo del estudio, tamańo de la población estudiada y metodología empleada en el estudio) y 7 ítems5.
Escala MInCir-pronóstico (Metodología de Investigación en Cirugía). El grupo MInCir, publicó en 2009, una propuesta válida y confiable, para la realización de revisiones sistemáticas y meta-análisis en escenarios de pronóstico, historia natural y curso clínico; con diferentes tipos de diseńos (incluidos los Estudios de Cohorte). Permite evaluar calidad metodológica. Está compuesta por 4 dominios (diseńo del estudio; tamańo de la población estudiada; metodología empleada en el estudio; y análisis y conclusiones) y 11 ítems5.
CONCLUSIONES
Los estudios de cohorte son una herramienta de gran utilidad para evaluar hipótesis de asociación en los casos donde una asignación experimental en seres humanos es imposible o antiética. El diseńo del estudio permite establecer si la exposición precede al desenlace y si la aparición del desenlace es diferencial entre grupos con diferentes niveles de exposición.Es un estudio eficiente para estudiar condiciones en salud comunes y con períodos de latencia cortos. La principal utilidad de los estudios de cohorte es la evaluación de causalidad, es encontrar la evidencia de asociación causal entre factores de riesgo y muchas de las enfermedades crónicas no transmisibles; permite además, estimar de forma válida riesgos de aparición de eventos (proporciones de incidencias), tiempos de supervivencia, tasas y densidades de incidencias.
El problema de los estudios de cohorte es su alto costo y periodos de seguimiento prolongados para observar el evento de interés especialmente en estudios de diseńo prospectivo, una forma de mitigar esta falencia es realizar un tipo de diseńo retrospectivo o ambiespectivo controlando los sesgos al máximo para mejorar la validez de los resultados.
Existen herramientas recientemente disponibles para evaluar de manera crítica la conducción, diseńo, resultados y conclusiones de los estudios de cohortes como las guías STROBE y la propuesta MOOSE. El presente es una revisión de la literatura clásica y actual accesible en el tema de estudios de cohorte que permite al lector de cualquier nivel de aprendizaje entender de forma clara y precisa las características, aplicaciones, ventajas, desventajas, diseńo y análisis de estudios de cohorte.
REFERENCIAS
1.- Vallejo M. El diseńo de investigación: una breve revisión metodológica. Arch Cardiol Mex. 2002:8-12.
2.- Ponce EL. Estudios de cohorte.Metodología, sesgos y aplicación. salud pública de méxico. 2000:mayo-junio.
3.- Gordis L. Epidemiology. Third Edition. Baltimore, Maryland: Elsevier Saunders; 2004.
4.- Fletcher R. Clinical Epidemiology. The Essentials. Fourth Edition. Baltimore: Lippincott Williams & Willkins; 2005.
5.- Salazar P. Estudios de cohortes. 1Ş parte. Descripción, metodología y aplicaciones. Rev cir. 2019:482-93.
6.- Ruiz A. Epidemiologia Clinica. Bogotá, Colombia: Médica Panamericana; 2004.
7.- Ruiz A. Epidemiologia Clinica. 2da edición. Bogotá, Colombia: Médica Panamericana; 2015.
8.- Pública. FdCMÁdS. Curso de Epidemiología Clinica. Cuyo, Argentina: Universidad Nacional de Cuyo; 2005.
9.- Cuschieri S. The STROBE guidelines. Saudi J Anaesth. 2019 Apr;13(Suppl 1):S31-s4. PubMed PMID: 30930717. PMCID: PMC6398292. Epub 2019/04/02. eng.
10.- von Elm E, Altman DG, Egger M, Pocock SJ, Gřtzsche PC, Vandenbroucke JP. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) Statement: guidelines for reporting observational studies. Int J Surg. 2014 Dec;12(12):1495-9. PubMed PMID: 25046131. Epub 2014/07/22. eng.
11.- Stroup DF, Berlin JA, Morton SC, Olkin I, Williamson GD, Rennie D, et al. Meta-analysis of observational studies in epidemiology: a proposal for reporting. Meta-analysis Of Observational Studies in Epidemiology (MOOSE) group. Jama. 2000 Apr 19;283(15):2008-12. PubMed PMID: 10789670. Epub 2000/05/02. eng.
CORRESPONDENCIA:
Ángela María Benjumea Salgado MD
Universidad de Caldas.
Manizales (Caldas). Colombia.
Email: ambsco4 @ gmail.com